
Task Objectives
The primary goal of this workshop is to critically examine the unseen mechanisms of social media platforms by tracing the complete journey of personal data. By deconstructing the lifecycle of data, the aim is to move beyond the role of passive user. We will view "black box" of algorithmic processing through three distinct lenses:
- Task 1- Input: This task involves locating and exporting personal data logs (e.g., via Instagram’s 'Privacy Centre') to distinguish between content we share and generative data. The aim is to determine what platforms "see and do not see."
- Task 2- Output: To critically assess our "algorithmic identity" by examining the ad preferences and inferred categories generated by platforms like Google and Instagram. The objective was to observe how algorithmic pattern recognition translates our online activity into simplified marketing components. For example, being categorized as a "parent of toddlers" or having an interest in specific clothing items.
- Task 3- Process: To perform a manual reverse-engineering experiment based on David Sumpter’s Outnumbered. By manual scraping and classifying 15 posts from 32 friends into fixed categories, we will step into the algorithm's shoes and think like a machine.
My Objective (Self-Initiated Work)
While the official task requires me to populate David Sumpter’s spreadsheet with 480 data points, my personal objective is to duly note when I fail to categorise the posts. I want to document the specific moments where the system breaks down. Sumpter provides 13 rigid boxes, but human expression rarely fits neatly into one. My goal is to track the posts that defy binary classification. This will allow me to observe how the algorithm's "clean" categorisation ultimately results in a flawed digital identity.
Algorithmic identity: the you you are
Cheney-Lippold (2011) talks about how algorithms classify people into categorizations based on their online activities by which they create a “new algorithmic identity” for each one of us.
“An identity formation that works through mathematical algorithms to infer categories of identity on otherwise anonymous beings” (Cheney-Lippold, 2011).
Labelling people with a new identity and categorizing them into certain groups is through a marketing logic of consumption. Lippold compares this with the consumer discrimination that happened earlier using census-laden geographies.
She writes, “Mathematical algorithms allowed marketers to make sense out of these data to better understand how to more effectively target services, advertisements, and content” (Cheney-Lippold, 2011).
Previous scholarship on social media algorithms has largely focused on user theories regarding their function (DeVito et al., 2018, cited in, Taylor and Choi, 2022) and their specific impact on marginalized communities, particularly LGBTQ+ users (DeVito, 2022; Simpson & Semaan, 2020, cited in, Taylor and Choi, 2022).
Since this body of work indicates that algorithmic categorisation is integral to formation of identity (Lee et al., 2022, cited in, Taylor and Choi, 2022), the interaction between users and these systems fundamentally shapes their sense of self.
The rapid expansion of the digital landscape has prompted another methodological shift. Rather than depending on human sources to categorize consumers, marketers are now employing algorithms to generate identity labels (Shen et al., 2025).
Prominent examples of this trend include Airbnb, which derives travel identities from personality tests and user history (Airbnb, 2017, cited in, Shen et al., 2025), and Starbucks, which has utilized MBTI personality types to tailor product recommendations (DeVries, 2016,cited in, Shen et al., 2025). By implementing these identity-based marketing strategies, brands not only enhance the consumer's enjoyment and self-recognition but also foster a deeper emotional resonance and connection with the company (Papaoikonomou et al, 2016, cited in, Shen et al., 2025).
In order to further explore the identities our algorithms have created for us, we checked our ad preferences for Google in its Google Ad Centre. The results were quite astonishing.
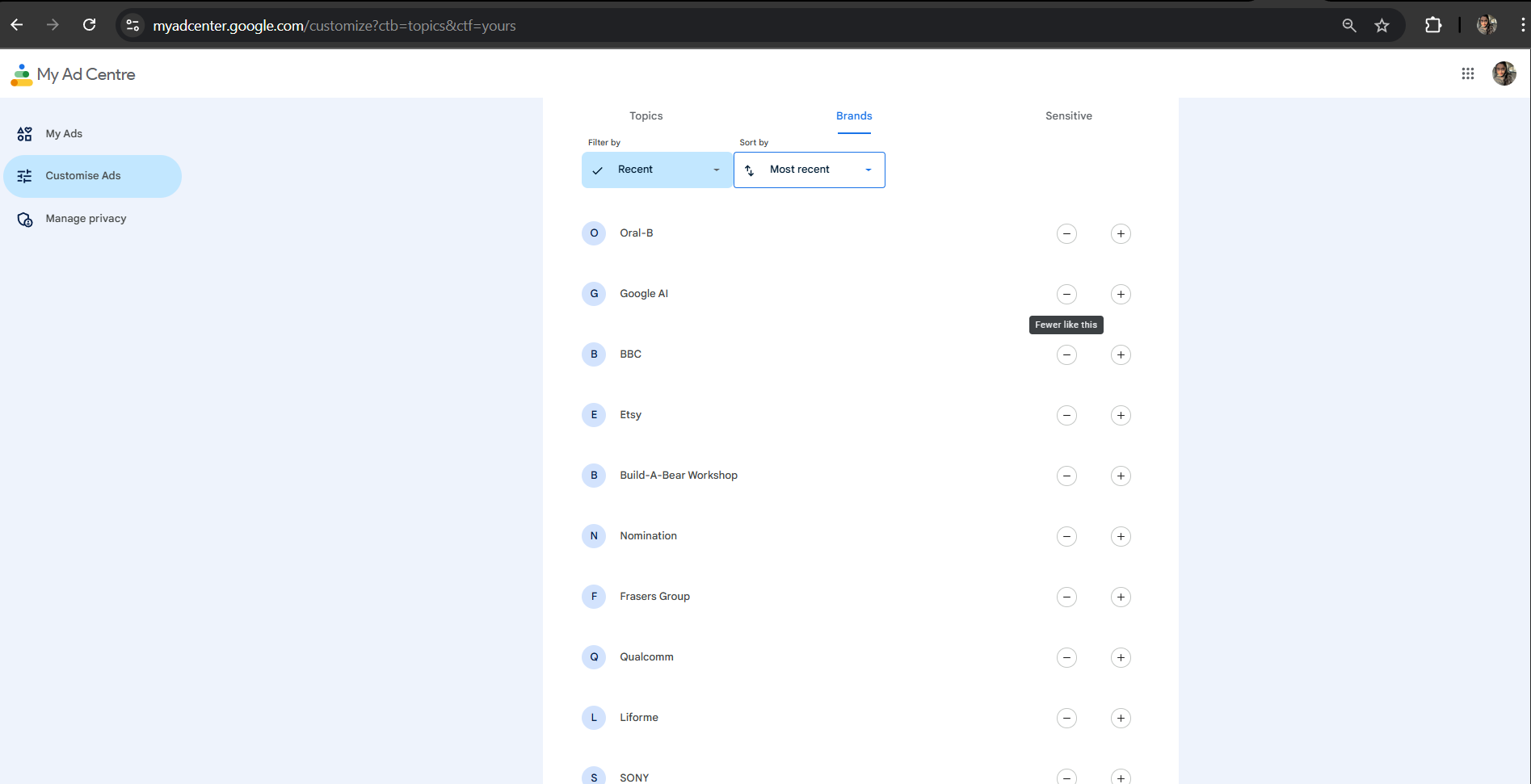
Figure 1: A snapshot of all the ads of brands Google "thinks" I would prefer to watch. It listed Etsy, Qualcomm, BBC, Build-A-Bear Workshop etc... I haven't even heard of some of these brands which makes this list quite weird.
THE INSTAGRAM IDENTITY
Upon exporting my Instagram metadata, I was struck by the sheer volume and granularity of the data retained by the platform. The 1GB archive was meticulously organized, containing a labelled record of my digital footprint. This included precise geolocation data (latitude and longitude), device specifications, and timestamps for every login. Furthermore, the file preserved a complete history of my interactions, ranging from every ad viewed and post liked to private chat logs and even media that I had previously deleted.
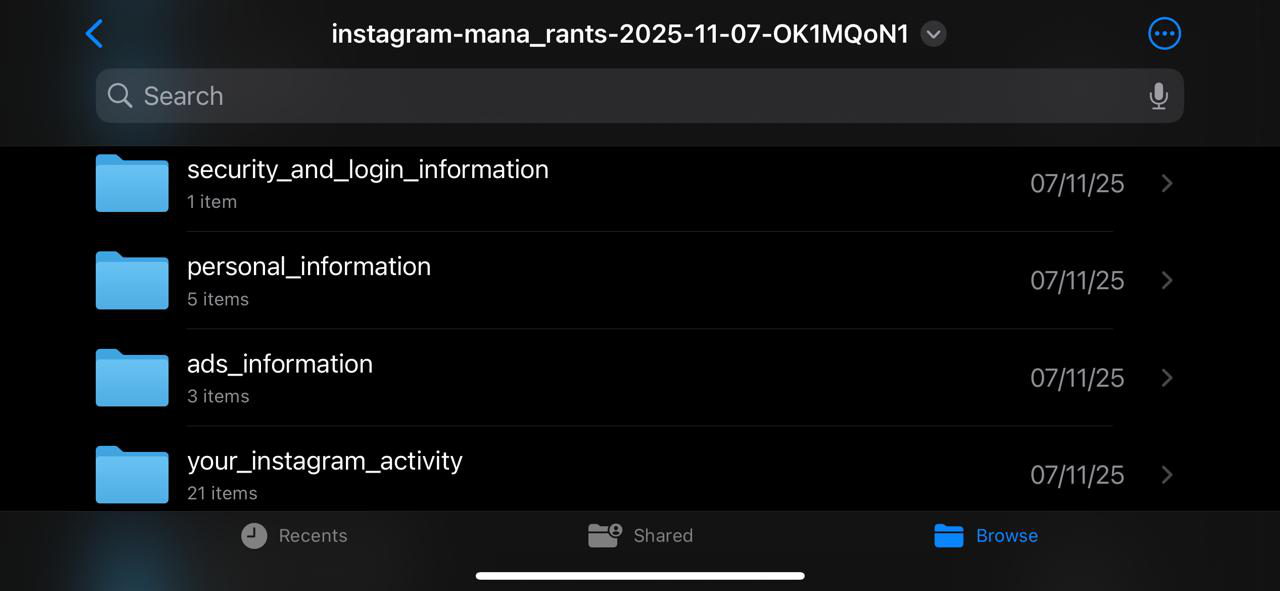
Figure 2.1: A snapshot of the files arranged in my Instagram metadata export file.
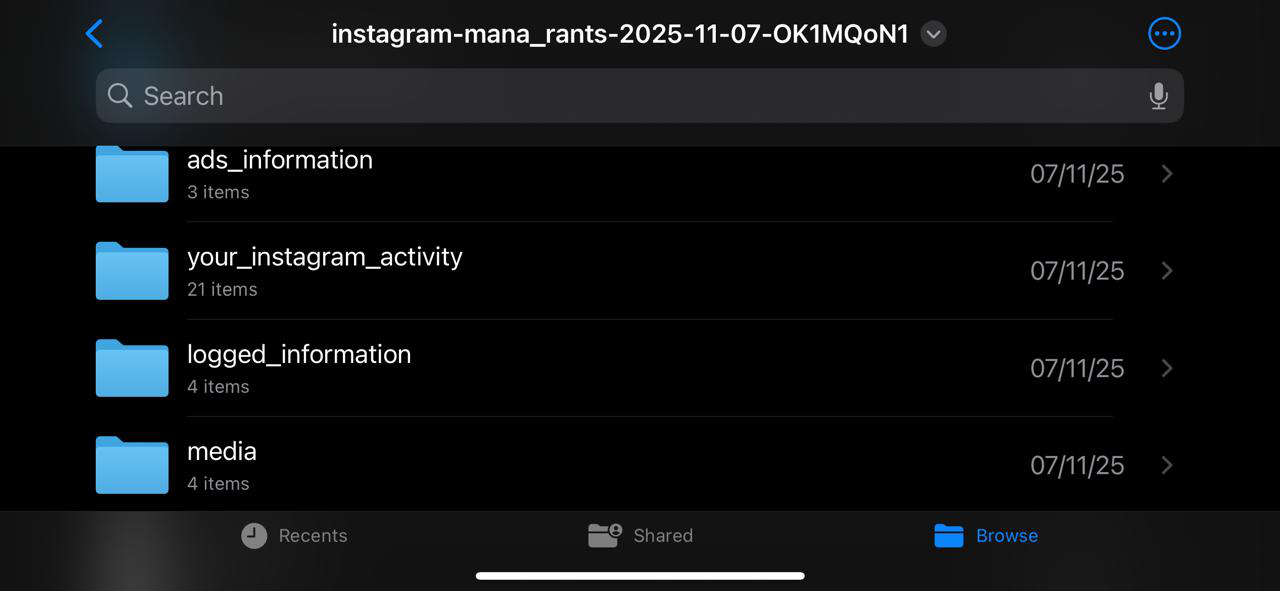
Figure 2.2: A snapshot of the files arranged in my Instagram metadata export file.
There was a folder that intrigued me, named "Recommended Topics. Its description read, "A collection of topics determined by your activity on Instagram that is used to create recommendations for you in different areas of Instagram, such as reels, feed recommendations, and shopping." Here's the top 10 on my list of "recommended topics:
- Car Racing
- Fish
- Basketball
- Alligators & Crocodiles
- Video Games
- Fashion Products
- Boxing
- Vacation & Leisure Activities
- Action TV & Movies
- Combat Sports
I found the breadth of these topics quite remarkable. There is almost a sense of validation in seeing the algorithm interpret my behavior as complex and varied. It credited me with an eclectic mix of interests that spans from fashion and racing to wildlife and martial arts. Algorithms are generally perceived as objective and unbiased. Users place greater trust in their ability to accurately define identity, and this belief leads individuals to view algorithm-generated labels as a closer reflection of their true nature (Shen et al., 2025).
Thinking like the algorithm
Since my Instagram account is relatively new, I only have 15 people I follow. Hence my Sumpter's matrix is only half the size it is supposed to be. But I tilll have a few observations.
.png)
Figure 3: A snapshot of my Sumpter's matrix.
As I attempted to sort my friends' Instagram posts, I realized that most content defies a single label. Human emotion is too complex to be boxed in. A post is often a blend of feelings. Simply categorizing something as 'Lifestyle' felt wrong when the image was really about the joy of doing something one loves.
Moreover, the numbers often told a false story. The data might paint someone as a huge extrovert online, while in reality, they are quite the opposite. It became clear that there is a vast difference between who people are online and who they are in person. This is a human nuance that an algorithm will never truly understand.
My analysis highlights the argument that (Cheney-Lippold, 2017, cited in, Kant, 2020, p.14), algorithms do not merely reflect our existing identities but actively construct them through computational categories.
When we rely on these metrics, 'we are data,' defined not by our complexity, but by the system’s labels. In order to extend this, we can suggest that we have become 'speculative selves' who are constantly waiting for platforms to verify who we are (Hearn, 2017, cited in, Kant, 2020, p.14).
Ultimately, the danger is that we begin to see ourselves and our friends through the 'eyes of the algorithm,' accepting these distorted digital profiles as the truth rather than seeing the complex human beneath (Butcher, 2017, cited in, Kant, 2020, p.14).
References
- Cheney-Lippold, J. 2011. A new algorithmic identity: Soft biopolitics and the modulation of control. Theory, culture & society. 28(6), pp.164–181.
- Kant, T. 2020.Making It Personal : Algorithmic personalization, identity, and Everyday Life [Online]. New York: Oxford University Press. [Accessed 26 November 2025]. Available from: https://books.google.co.uk/books?id=TjLNDwAAQBAJ&dq=algorithmic+identity&lr=&source=gbs_navlinks_s.
- Shen, Z., Hu, Y. and Yin, Y. 2025. Algorithm‐Generated Identity Labeling Promotes Identity‐Consistent Product Preferences. Psychology and Marketing. 42(6).
- Taylor, S.H. and Choi, M. 2022. An Initial Conceptualization of Algorithm Responsiveness: Comparing Perceptions of Algorithms Across Social Media Platforms. Social Media + Society. 8(4), pp.1–12.